数据库数据处理的类型 最后更新时间:2024年05月28日 数据库处理有两种基本类型:ACID和BASE。ACID(英文中有“酸”的意思)和BASE(英文中有“碱”的意思)是pH酸碱度范围对立的两端,因此这个巧合的命名对于理解它们也有所帮助。CAP定理用于界定分布式系统与ACID(强调一致性C)还是与BASE(强调可用性A)更加接近。 ### ACID 缩写词ACID是在20世纪80年代末期出现的一个合成词,含义是保证数据库事务可靠性不可或缺的约束。数十年来,它为事务处理提供了坚实的基础[1]。 1. 原子性(Atomicity)。所有操作要么都完成,要么一个也不完成。因此,如果事务中的某部分失败,那么整个事务就都会失败。 2. 一致性(Consistency)。事务必须时刻完全符合系统定义的规则,未完成的事务必须回退。 3. 隔离性(Isolation)。每个事务都是独立的。 4. 持久性(Durability)。事务一旦完成,就不可撤销。 ACID主要用在关系型数据库中。 在关系型数据库存储中,ACID相关技术是最主要的工具,通常采用SQL作为接口。 ### BASE 数据增长规模空前,数据新增种类繁多。记录和存储非结构化数据的需要,读优化和数据负载性能需要以及后续在横向扩展、设计、处理、成本及灾难恢复方面有更大灵活性的需要等,这些都走向了与ACID正好相反的一方。BASE应时而生,满足了这些需要。 1. 基本可用(BasicallyAvailable)。即使节点发生故障,系统仍然能保证一定级别数据的可用性。数据可能过时,但系统仍然会给出响应。 2. 软状态(Soft State)。数据处于持续流动的状态,当给出响应时,数据不保证是最新的。 3. 最终一致性(Eventual Consistency)。数据在所有节点、所有数据库上最终状态是一致的,但并非每时每刻在每个事务里都是一致的。 通常在大数据环境里会使用BASE类型的系统,如大型互联网公司和社交媒体公司。因为,它们的业务场景任何时候都不需要立即准确地拿到所有数据。表6-1总结了ACID和BASE的区别。 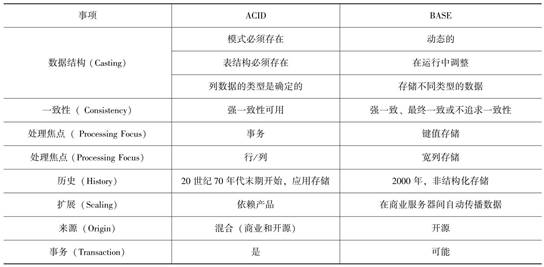 ### CAP CAP定理(也称为“布鲁尔定理”)是集中式系统在朝着分布式的系统方向发展过程中提出的理论。CAP定理指的是分布式系统不可能同时满足ACID的所有要求。系统规模越大,满足的要求点越少。分布式系统必须在各种属性(要求)间进行权衡。 1. 一致性(Consistency)。系统必须总是按照设计和预期的方式运行。 2. 可用性(Availability)。请求发生时系统时刻都保持可用状态,并对请求作出响应。 3. 分区容错(PartitionTolerance)。偶尔发生数据丢失或者部分系统故障发生时,系统依然能够继续运行提供服务。 CAP定理指出,在任何共享数据的系统里,这3项要求最多只可能同时满足其中两项。通常用“三选二”来说明。 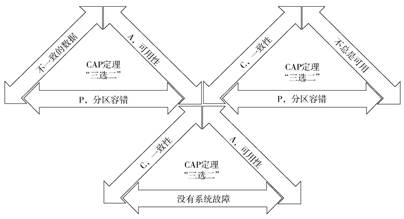


Comments | NOTHING